

 |
在大部分人看来,人工智能是个有些「科幻」的词汇,代表小说电影中和人类长相相似、或温柔或冷酷的机器人。
稍微熟悉一点,这份印象又变成冷冰冰的 GPU 阵列、复杂多层的神经网络和一大串佶屈聱牙的专有名词。能接触它们的除了工程师,就是科学家。
也许这份印象需要再度刷新一次——人工智能,真的需要不少「人工」。
一
秦娇今年刚满 30 岁,几个月前刚刚从呼叫中心跳槽到一家「数据加工」公司。虽然跨了行业,她并不觉得两份工作有什么不同,都是按照甲方的要求和己方的工作节奏,把人手安排到一个又一个项目中去。
 |
公司刚成立不到一年,眼下业务大多是标注数据,即根据项目方要求,人工为图片、视频和语音内容打标签、做标记。标注好的数据会被人工智能公司用来训练算法模型,然后应用到图像识别、语音识别等不同领域。
通常来说,数据标注得越准确、数量越多,模型的效果就越好。自然,产品的效果就会更好。
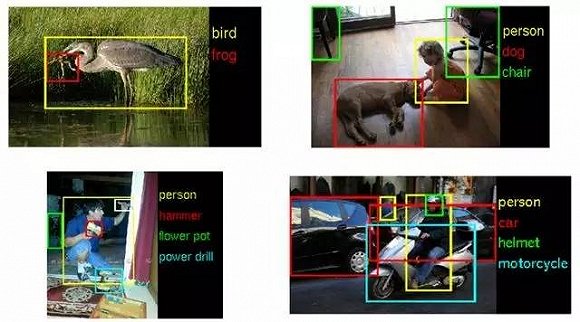
一旦要求质量,每个人的产出量就不会太多。熟练者平均一天可以标注 40 张图片,前提是只需要为图片中的物体打框、标注类别和前后关系。如果涉及到刻画建筑物边缘等复杂细节,一天标注 10 张已是极限。
 |
图片为简单标注方式的一种
数据庞大又开源,ImageNet 很快成为成为研究图像识别的首选。不论 Andrew Ng(吴恩达)还是 Jeff Dean,涉足这一领域研究者都使用过 ImageNet。但 ImageNet 有自己的弱点,标注框太大、标注方式少和不时出现的错误,使它难以被用来训练实际应用的算法模型。
人工智能公司们必须想尽办法,积累符合自身应用方向,标注得更细致、更准确的数据。在初创公司招聘工程师的需求中,「有收集标注数据的能力」有时也会被写进其中。某种程度上,高质量的标注数据决定了一家人工智能公司竞争力。
尽管互联网的确催生了浩如烟海的内容,但标注这件需要耐心和专注的「小事」,暂且还要靠人的帮忙。
二
在专业的数据标注公司出现前,众包平台往往是大部分公司的选择。
人们认为灵活性更高的众包方式能适应不稳定的数据需求,价格成本也更低。某知名数据众包平台据称拥有超过 5,000 名数据标注专员,单日可处理超过 200 万条数据,能「稳定提供数据标注服务」。
 |
数据标注是所有数据众包平台的核心业务,除此之外还有数据清洗、数据采集等等
通过数据交易平台购买已标注好的数据包也是一种选择。但问题似乎又绕回为什么人工智能公司要自己标注数据:不同的应用方向需要的数据内容不同,甚至标注方式也不同。
秦娇目前所在的这家公司,瞄准的就是这片市场——人工智能公司需要的数据既要根据需求定制,又要保证标注质量,同时数量还十分庞大。大部分人工智能公司自身和众包平台都无法同时满足这三种要求,因而诞生了专业的数据标注公司。
这家「数据加工」公司的一二层,全部是负责标注数据的员工。为满足不同订单需求,员工们被划分成不同小组:
有的小组负责勾画图片中人体的关节点,将复杂的瑜伽姿势抽象成点和线,可以用来训练识别人体体态的模型;
有的小组要为路况图片中的车辆、摩托车、自行车和行人打上边框,并标注行进方向和是否有遮挡,这类图片多用来训练智能安防摄像头的识别能力;
有的小组需要分毫不差的描绘建筑物的边缘,将静止画面中鳞次栉比的大楼一一分割,标注成不同的色块,这类数据多用在自动驾驶中车辆对环境的认知;
有的正将雷达扫描出的障碍物 3D 线条一一还原成实物,长方体是建筑、绿色的是树木,这些内容会被用来训练雷达数据和真实世界的关联性。
 |
标注作业有时并不简单,比如这种关联性标注
除图片外,这里还有负责视频标注的员工。她们需要从每段视频中抽出 10 帧,标注相近两帧中物体的方向和坐标的变化。这些数据也许会被用来训练机器对物体连贯性的感知,也许用来训练机器预判物体的位置变化。
与大部分制造业类似,这里的各个小组都有自己的管理者。管理者之上是项目经理,然后才是秦娇这样为数不多的高层管理者。员工「生产」的内容会经过质检人员的核验,全部合格后才会最终交付项目方。严格的流程和管理制度,保证了稳定的标注效率和质量。
「很多人认为大数据就是呼叫中心,我们发展的大数据和其他人不一样,整个贵州只有我们做数据精加工。」对于公司目前在做的业务,秦娇显得非常骄傲。
的确,这些结构化后数据,将成为这场人工智能大潮中的公司们的立足之本。不仅帮助它们提升模型的准确度、提升产品的可靠性,甚至影响它们的发展轨迹和融资进程。
三
「数据加工」公司所在地距「大数据之城」贵阳五十多公里,是一座只接受科技公司入驻的「数字小镇」。刚刚落成入驻率不高,加上位置偏远、人迹罕至,园区显得十分安静。
 |
小镇多是这样的彩色尖顶小楼,绿化丰富,十分安静
有趣的是尽管位处山林之中,小镇的隔壁有一间规模不小的高职学校,学校的学生构成了这家公司目前主要的员工来源。除上课外,学生们每天有大约 6 个小时可以工作,「易于管理、尽职尽责」是秦娇给这些学生的评价。
高职学校初建的目的是教育扶贫,因此学生们大多来自贫困山区,学校会提供不少补助和奖学金。在数据加工公司兼职赚来的钱不仅足够生活,有些学生还会拿出一部分补贴家用。偶尔这份工作还能成为职业跳板,「我们的学生踏实又努力,有的去北京实习,因为熟悉标注工作、又认真,反馈回来说比同样实习的北京大学生强得多」。
学校走廊的墙上也贴着不少相似的学生案例。在描述学生们入学前情况的文字中,不可避免的包含着「贫穷」、「双亡」、「残疾」等词汇。其中一张照片中父亲、母亲和学生坐在寨楼的木板地上,身后昏暗的空间里没有任何摆设;另一张照片中的学生搂着患病的哥哥;还有一张照片,面无表情的学生正坐在床一样的地方,背景是用黑白报纸糊着的墙。后来,她们都凭努力改变了自己和家庭的命运。
对这份工作能带给学生的机会与回报,「数据加工」公司的 COO 李政同样十分笃定。但比起秦娇对于数据标注行业的信心满满,他则显得有些忧心忡忡。毕业于北京航空航天大学的他清晰的意识到,现阶段的数据标注还是劳动密集型产业,和南方工厂没什么不同。学生们都只是流水线上来料加工的一环,处在价值链的底端。只有向前一步,找到更深入行业的业务模式,才能从已经开始热络的数据加工行业中脱颖而出。
摸索了近一年,李政拓展了包括采集数据在内的不少业务。所谓采集数据,是指自主拍摄符合项目方要求的人像图片,如一个人正面、45 度、60 度以及佩戴各类装饰物的照片。这些图片可以用来训练计算机对于同一张人脸在不同状态下识别的准确性和关联性,是目前大部分专注人脸的计算机视觉公司都有的需求。
 |
有时,表情也在规定在数据采集的要求中
在自己搭建的摄影棚中,「数据加工」公司已经完成了好几份订单。主角当然还是学生们,她们排队依次进入影棚,按照要求摆好姿势拍下几张照片后,再分别戴上口罩、墨镜、帽子继续拍摄。一套照片往往包含 10 几张,一天能拍摄 100 多套。比起安防公司自己搜集或拍摄照片,这套标准流程和足够的样本数(学校至少有上千个学生)的确有不小竞争力。
除此之外,她们还可以承接小语种的语料收集工作。地处西南、临近东南亚,当地的人际关系链和频繁的商务交往能提供不少便利。
「只做来料加工肯定不行,」李政非常坚定,「我们最近正在培训一些技术人员,懂技术才能和项目方更好的沟通需求,把需求更好的描述出来,我们才能更好的满足。」
四
「标注真的是个辛苦活。」提起「数据标注」四个字,华院数据的首席科学家尹相志不禁咧了咧嘴。
几个月前,华院数据刚刚举办过一次大数据应用比赛,包含识别复杂图像中的动物、通过行车纪录仪的图像还原驾车操作场景等多个环节。在「通过卖场货架图片自动计算产品的货架占有率」这项测试中,她们拍摄了 1600 多张真实的货架图片作为原始数据。
比赛的目的,是通过不到两千张的「小数据样本」,实现往往需要大量样本才能实现的图像识别。为了让比赛的难度不那么「变态」,她们还为选手们提供了「精细化标注」后的货架图片——所谓精细化标注,就是货架上每一包紧挨着的零食、泡面,都要延边缘仔细划分。
 |
图中左侧为从真实货架照片中挖取出的同类商品碎片;右侧为对货架上不同商品的标注,每种灰度对应一种商品
「深度学习最大的问题还是样本数,这里考的其实是怎样通过小样本进行学习。」通过这项挑战的诀窍之一,是将原本 1000 多张图片根据提供的边缘裁切保留纯粹的产品图像,透过数据增强技术放大到数十万张,再根据这些增强后的图片建模就可以减少误差。精细化标注不仅能帮助解决样本稀少的问题,对于过往需要几十万图片才能训练模型的模式也带来了启发。
不过精细化标注并不是什么容易事,这一千多张图片的标注耗费了 12 个人大半个月时间,负责标注工作的组员「几近崩溃」。如果有人能承担复杂标注这项令人「崩溃」的工作,并善于满足复杂的标注要求,人工数据标注能成为一项长远发展的产业吗?
「近期需求还是很大,」尹相志想了想,「但这个行业可能只有 5 年时间,大家都在想各种办法,比如开源,比如小样本学习本身。」
除了小样本学习,人们也在思考是否能合成数据。图像识别领域的研究者们正在尝试通过图形学方法,制造出逼真的、和真正训练图像非常相似的图片。理论上这种方法能够产生大量直接带有标注的数据,但能不能「真实」,还需要图形学上的进步。
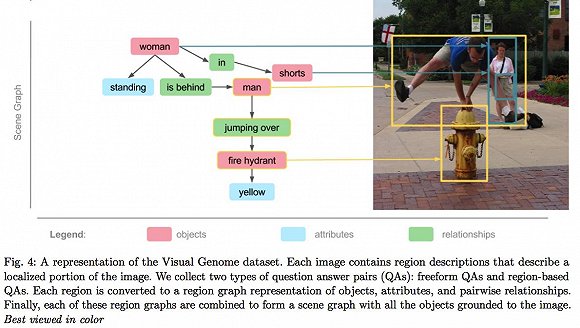 |
ImageNet 的缔造者李飞飞同样意识到精细化标注的力量,正在进行一份名为「Visual Genome」的工作。Visual Genome 有更多、更窄的框,更详细的名词标注,以及位置关系和动作关系。目前 Visual Genome 中有 10.8 万张图片。
对于数据标注这件不大不小的麻烦事,每个从业者都有自己的看法。有人讳莫如深,将话题转换成互联网是最庞大的数据集;但事实上所有人都知道采集到的数据无法直接使用。有人坦诚不少数据需要学生兼职或靠自己的员工标注,对质量的不满促使有些公司干脆成立了数据标注部门;还有人透露,如果用对了关键词,在淘宝也能找到不少外包商。
不过每个人或多或少都乐观相信,5 年后就不再需要这么多人力,无监督学习、小样本或者自动生成数据会发挥更大作用。
可那些倾注人们心血标记而成、精巧如艺术品的标注图片,5 年后的计算机,真的不再需要它们了吗?
五
在知乎「大公司里面有人专门负责标注数据吗?」问题下,共有 21 个回答。来自大公司的回答者们表示曾「发动全部门人对几万张图进行人肉打标」,或是将工作「安排在人力成本比较低的分公司」。小公司们则将数据「交给隔壁全是女性的部门标」,或是「省钱就自己人标了」。除此之外,交给外包公司是频率最高的选项。
从招聘网站发布的职位需求也可略窥一二。在智联招聘中键入「数据标注」,可以找到 60 个直接相关职位。在拉勾网则能找到近 400 个——管理外包团队等相关职位也被算入其中。以兼职为主题的豆瓣小组和百度贴吧,也从满屏的写软文、写小说、写评论,开始夹杂数据标注的兼职招募。
看起来,在人工智能行业火热、大量创业公司涌现的当下,数据标注是一门不错的好生意。
2009 年,张彤禾曾在《打工女孩》中描述过一群背井离乡,来到东莞独自打拼的女孩。她们刚刚十八九岁,甚至尚未成年,便离开学校在工厂里不分昼夜的工作。流水线上的女工,既不了解自己正在生产什么,也不知道自己的工作「秋西」(QC)就是「质量检测」。不论工作还是生存环境都相当恶劣,晚上去小吃街就算改善生活,往往也缺乏精神娱乐。
但与印象中打工者的刻板形象不同,她们既不短视,也不压抑。她们不在乎 15 个人共用一个房间,50 个人共用一个洗手间。占据她们头脑的是,多久才能存够买房子的钱?该如何晋升或者干脆跳到更有前景的岗位?所剩无几的周末,是该学习计算机、英语还是别的什么?
与马克思那份工人与生产物分离后,失去了满足和快乐的「资本主义的悲哀」不同,「分离」改变的不一定是她们的社会地位,而是她们的思想。花费时间制造的东西并不能代表制造者本身,赚来的钱花在了哪儿、让她们学会了什么技能、如何改变了她们,才更加重要。
「我们手上的 iPod、脚上的 Nike、肩上的 Coach,无形中改变了数百万人的工作、婚姻、生活和思想。」
也许数据标注同样如此。在探讨这个行业存在的合理性与是否能长久发展之前,能带给从业者的改变就已足够振奋人心。
但我们仍不能忘记这些人的付出。尽管她们面目不清,从未被人提起。
文中秦娇、李政均为化名
本文为机器之心原创,转载请联系本公众号获得授权。
 |




